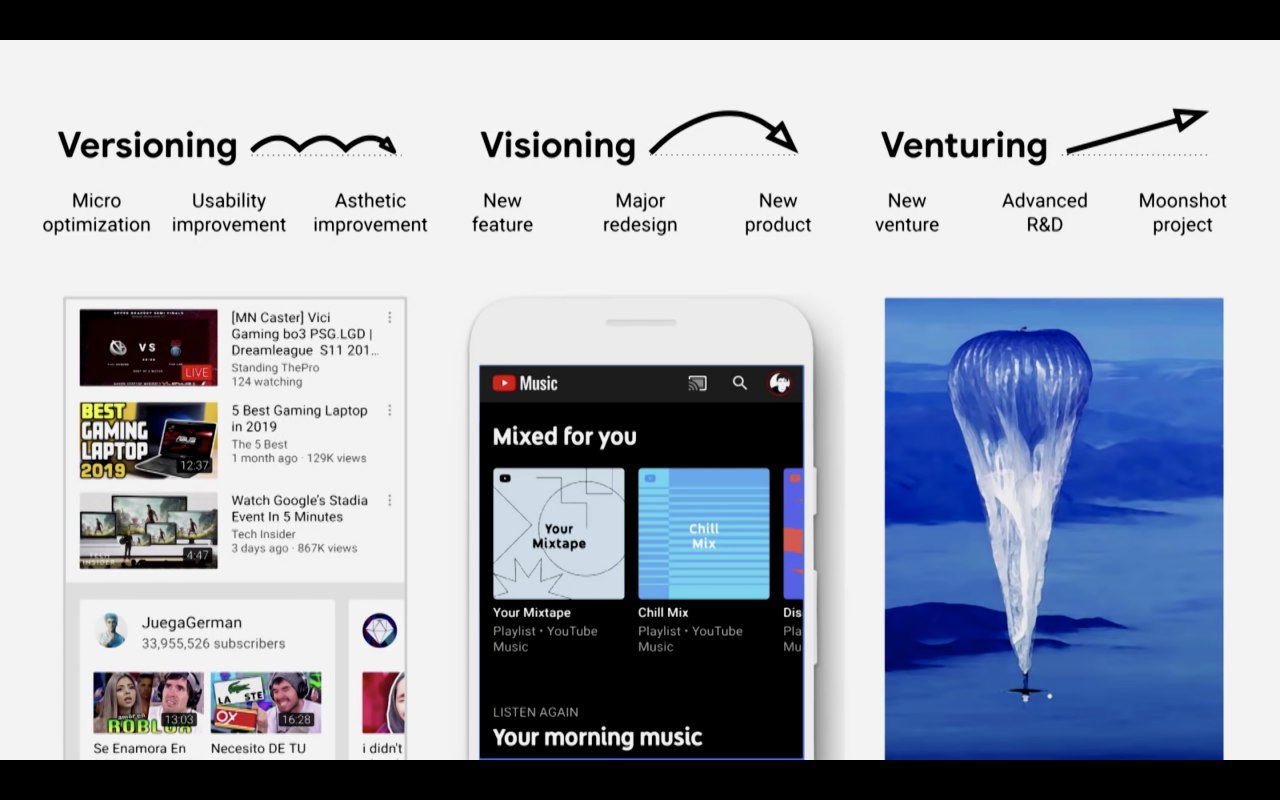
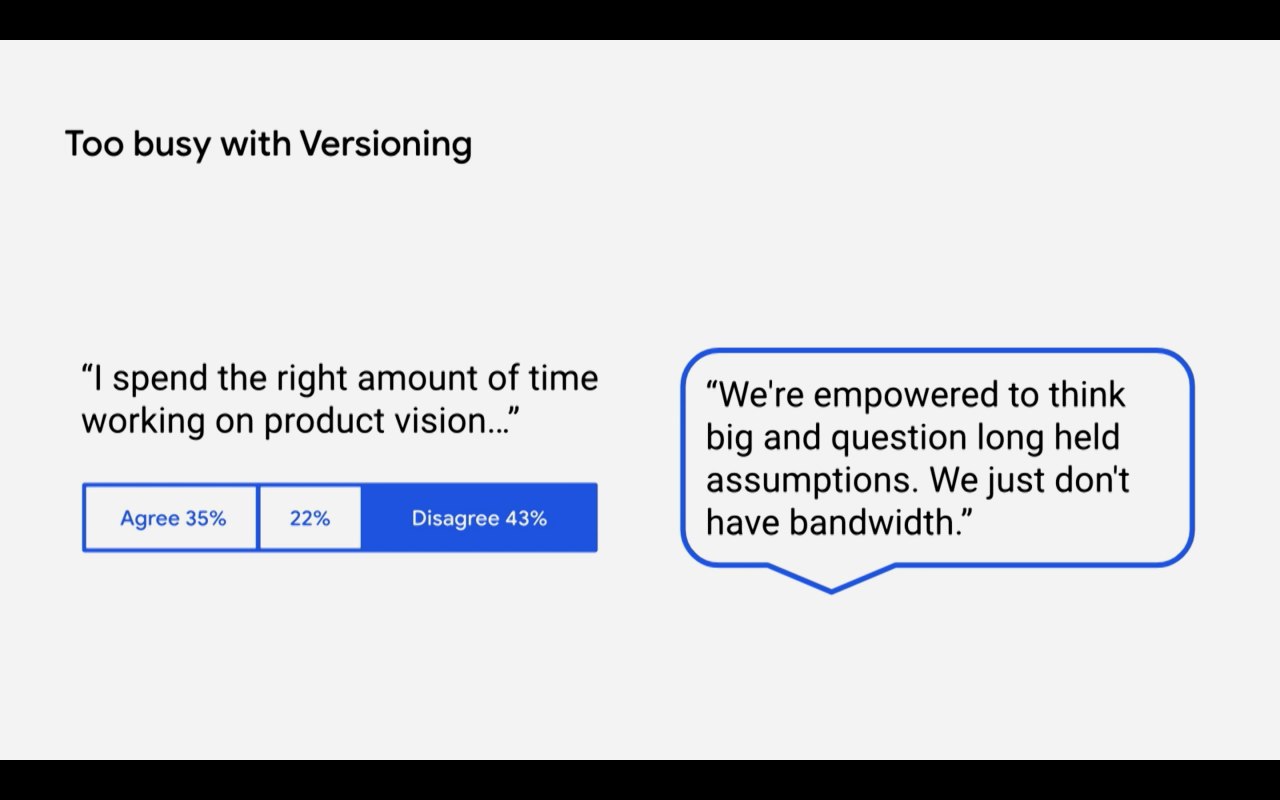
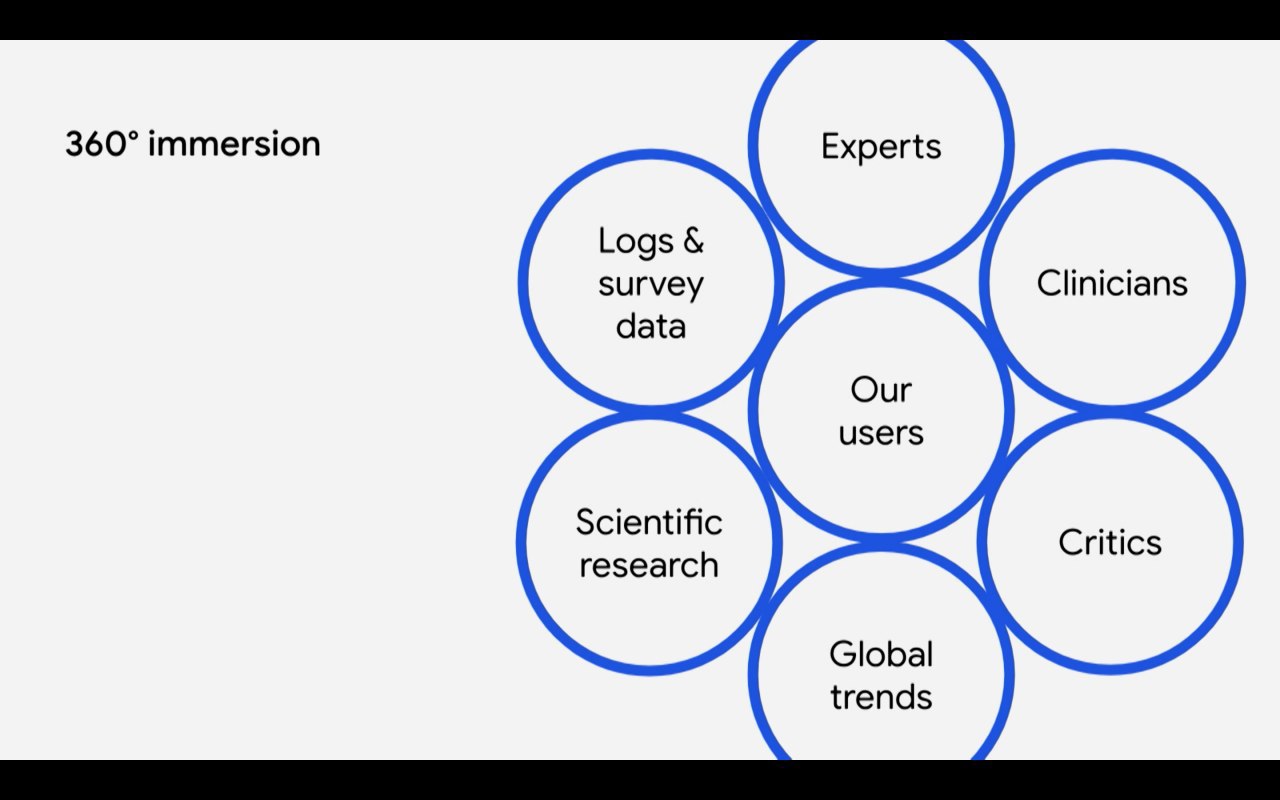
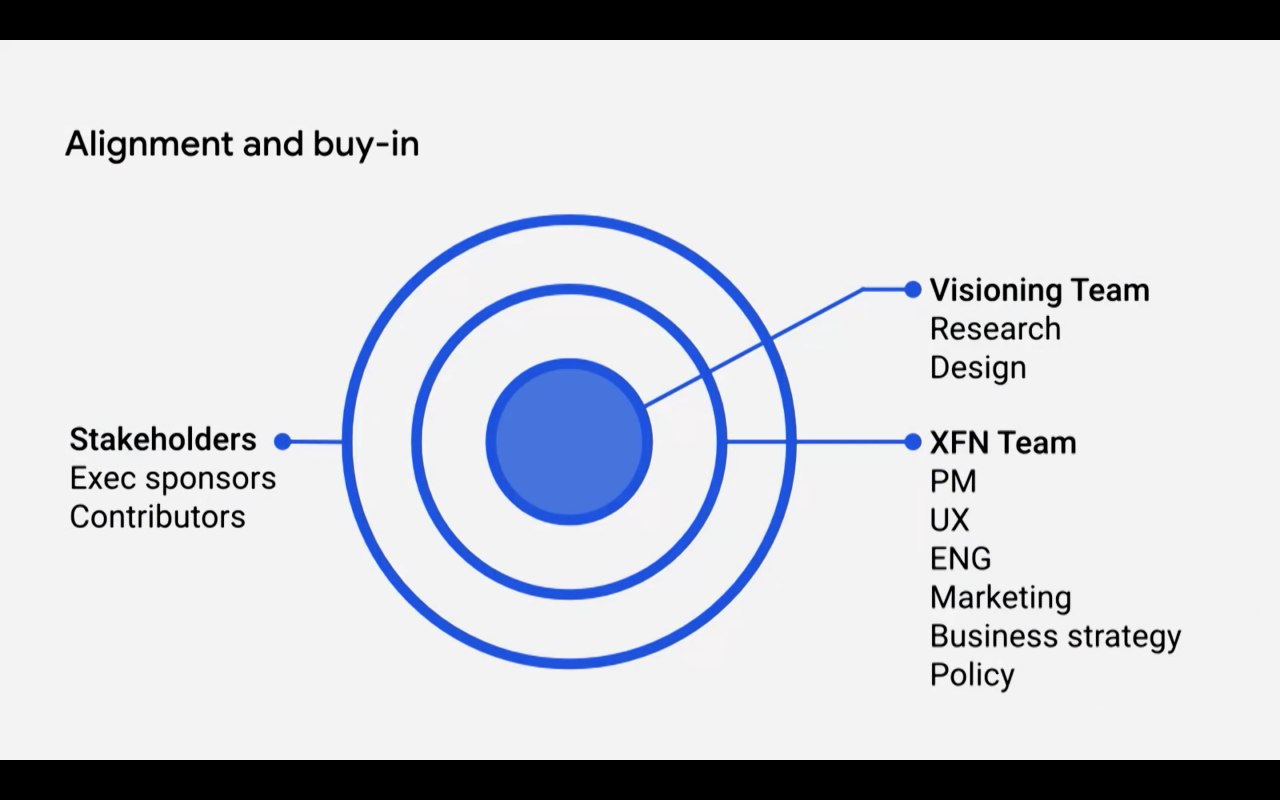
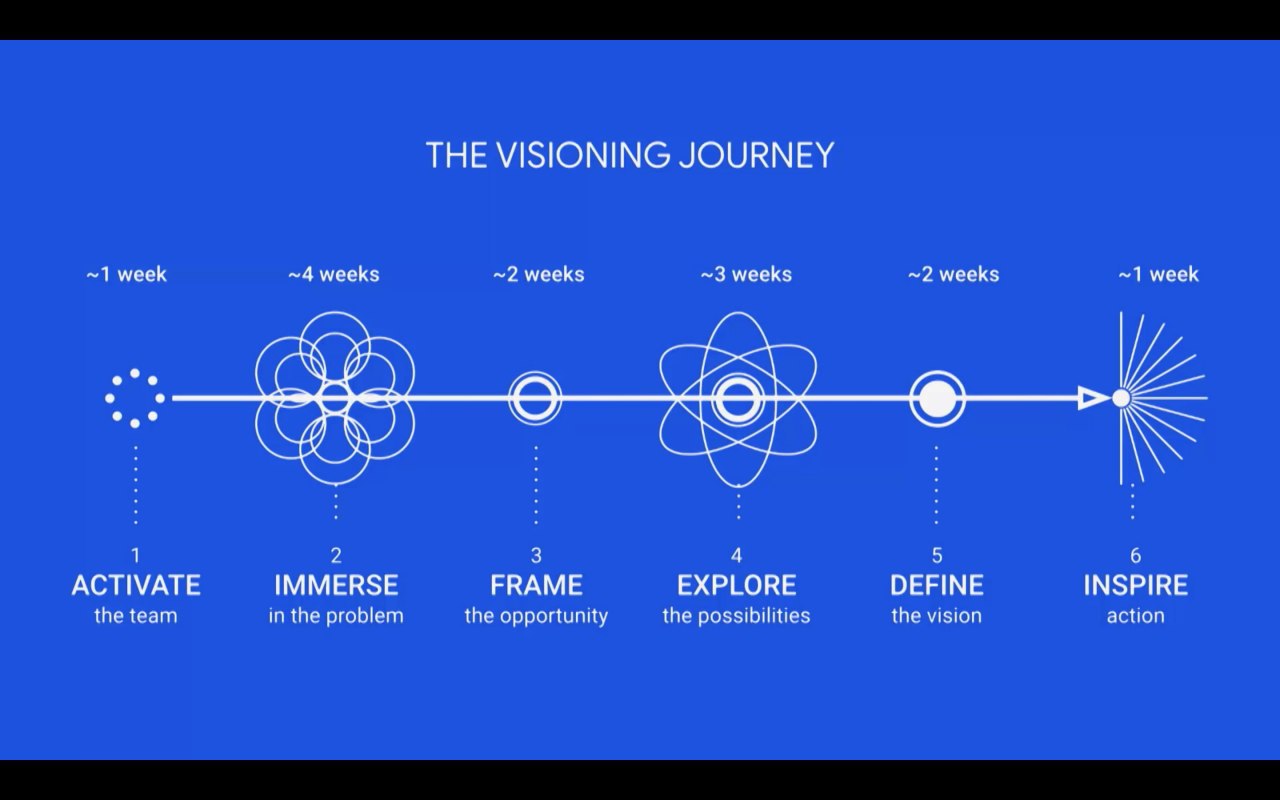
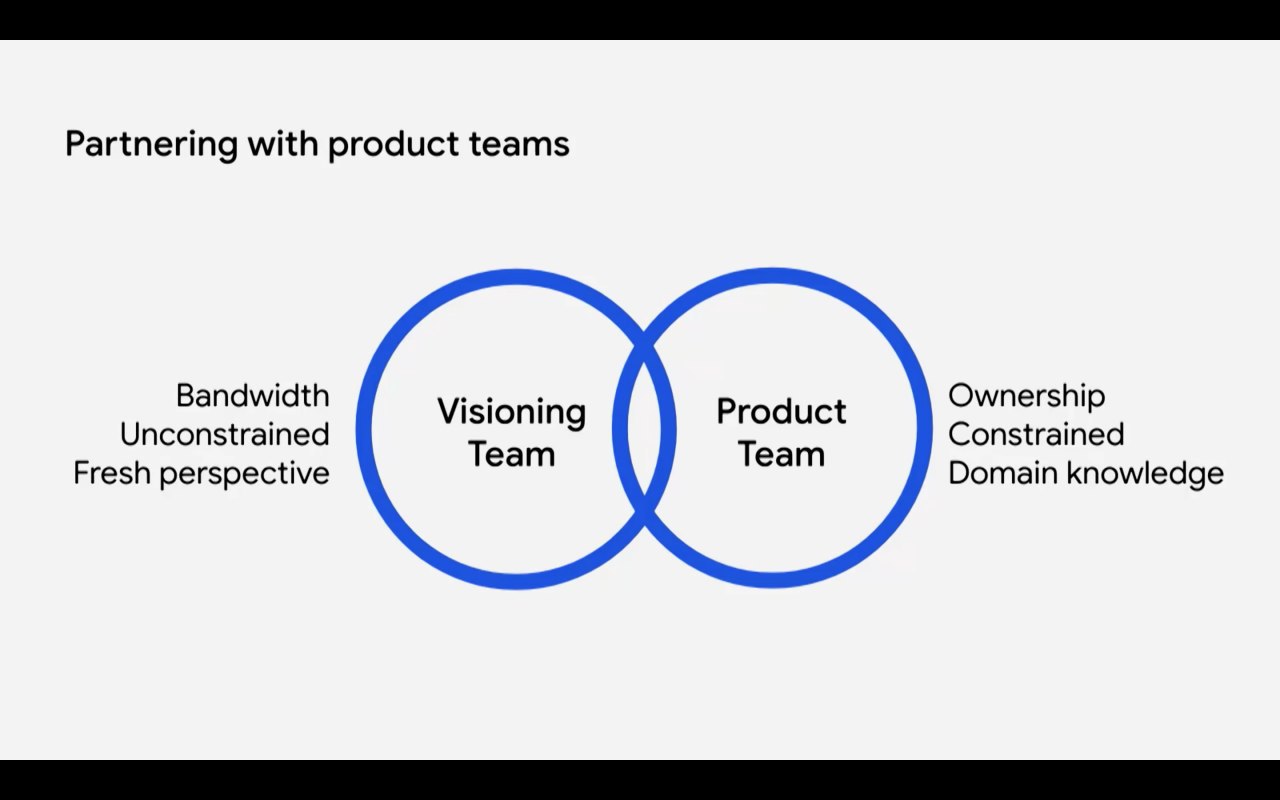
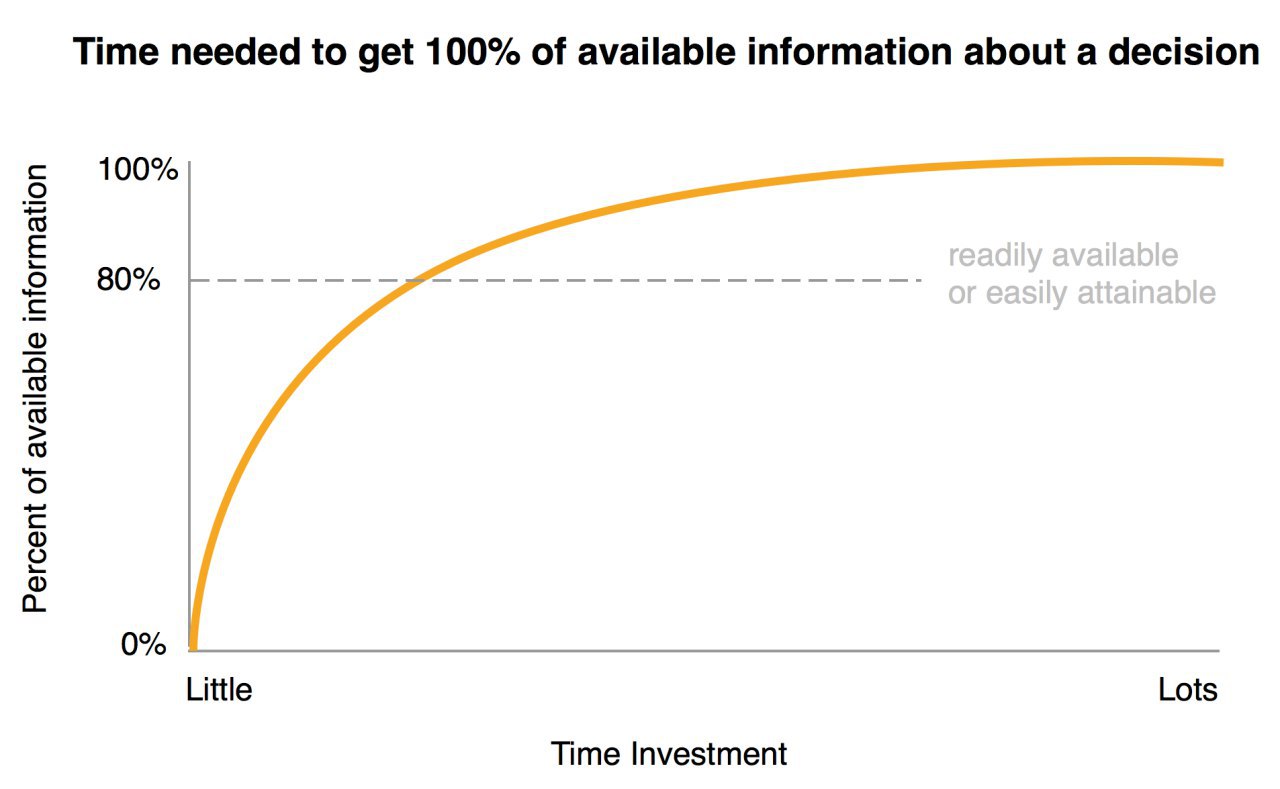
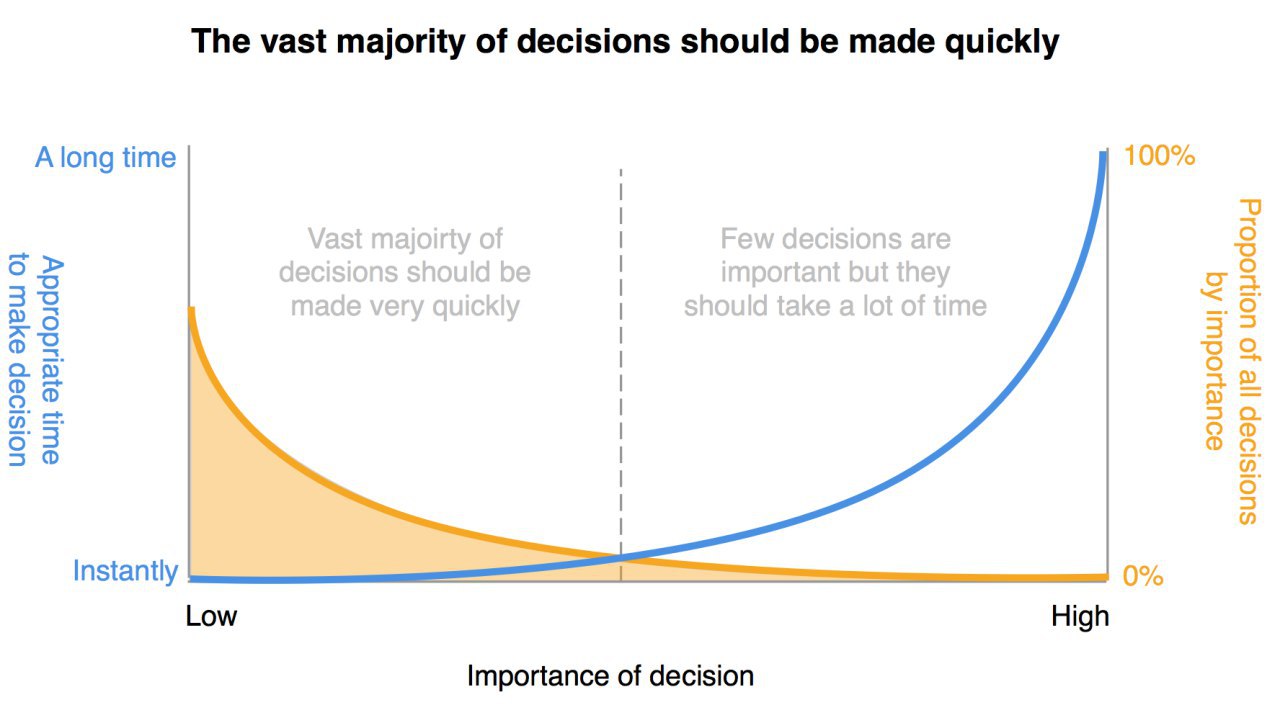
Две тех.философии
Бен Томпсон пытается систематизировать подходы разных компаний в области ИИ.
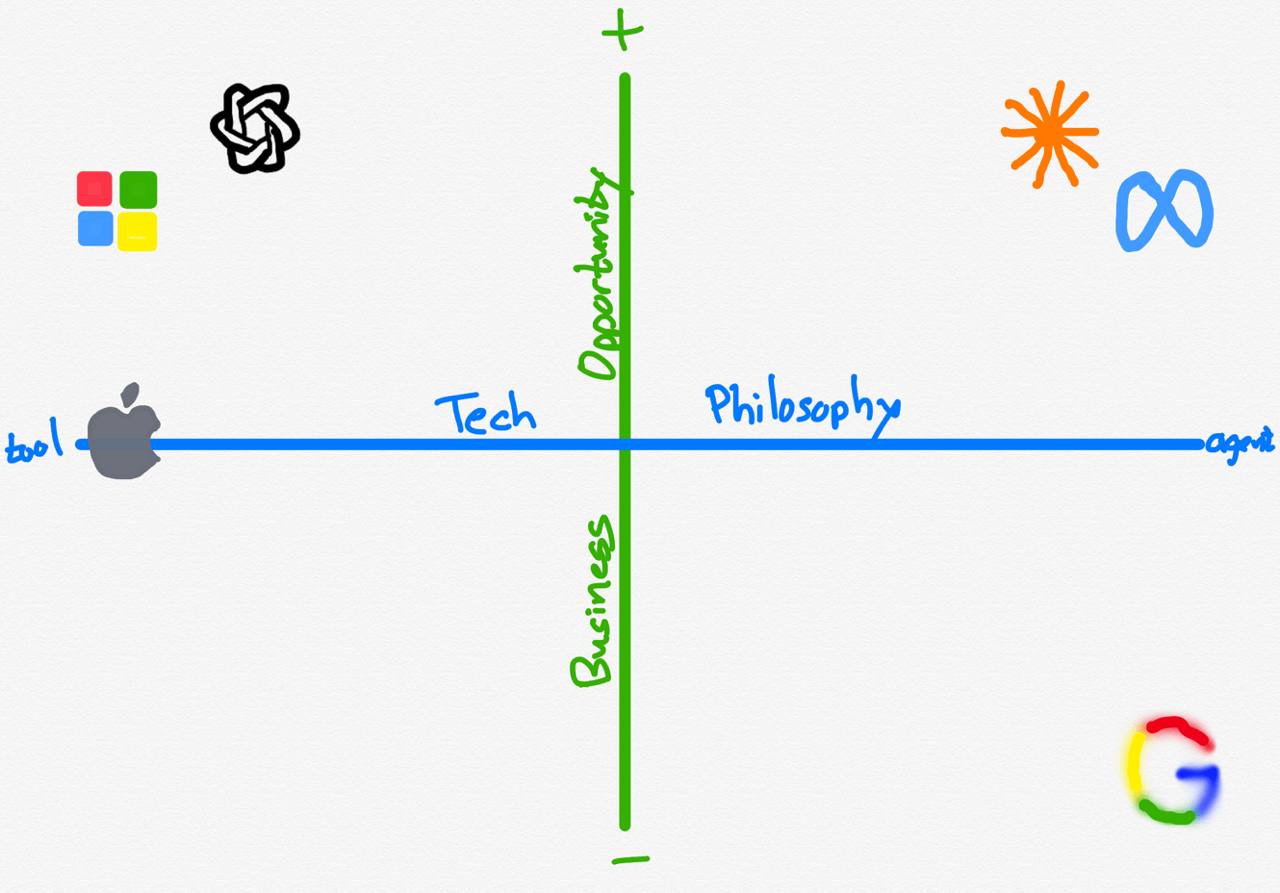
Он предлагает 2х2 матрицу с разбивкой по «философии в отношении ИИ» и «влияние на существующую бизнес-модель».
Если супер-кратко, то есть два лагеря:
- Софт (или ИИ в контексте 2025г от Рождества Христова) — это «the bicycle of the mind» как однажды выразился Стив Джобс еще до того, как стал носить черные водолазки. То есть, это человеческий усилитель.
- Софт/ИИ — это личный слуга, который делает вещи за человека.
И битву этих двух якодзун мы и наблюдаем в медийном и финансовом пространстве.
Бен подметил эти два лагеря еще в 2018 (а может и ранее) и периодически ссылается на это в текстах и развивает мысль.
Борьба за трактовки и интерпретации как может и должен выглядеть прислужливый ИИ разгорячилась где-то в 2022-м вместе с бумом LLM и технологии трансформеров.
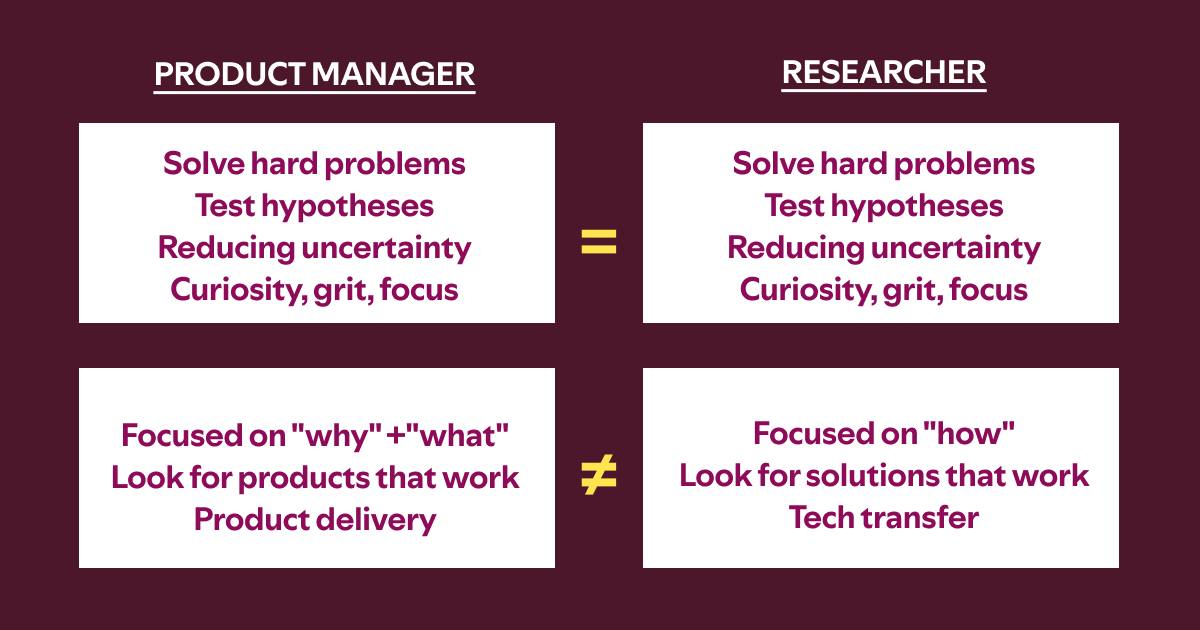
Источник бума технооптимисты, учёные и инженеры во главе с Эндрю Ыном (Andrew Ng). В 2024-м он предложил свои дизайн-паттерны для агентов. Технари взяли их на вооружение и понесли в треды на твиттере и в презентации к инвесторам. Anthropic нанимает штатного философа, чтобы стройно излагать кто они и зачем.
Но пятью годами раньше, кмк, тон дискуссии задавали в дизайнерском сообществе. На ум мне приходят отличные книги, конференции и статьи, где практики рассказывают как строить полезные человекоцентричные интеллектуальные продукты.
- книга Designing Agentive Technology: AI That Works for People (статья от автора)
- исследования и гайдбуки от People AI Research Group из Google
- еще в 2019м на ACM SIGCHI учёные и практики рассказывали как систематизируют опыт и делают полезные умные продукты.
Сейчас наблюдаю в нишевом проф.сообществе битву определений, виженов и стратегий.
Дизайнеры делают ответный выпад. Готовятся новые книги, прототипируются новые продукты, формируются стили и паттерны:
Если максимально упростить, то:
- условная «башня дизайнеров» развивает концепции «велосипедов для ума» и систем которым «мы делегируем рутину, но все равно контролируем исполнение»
- условная «башня программистов» топит за полную автоматизацию (алгоритмизацию, стандартизацию, упрощение?) большой части нашей жизни, где потенциально внимание человека вообще не будет нужно.
Кто победит? Как говорится, it depends.