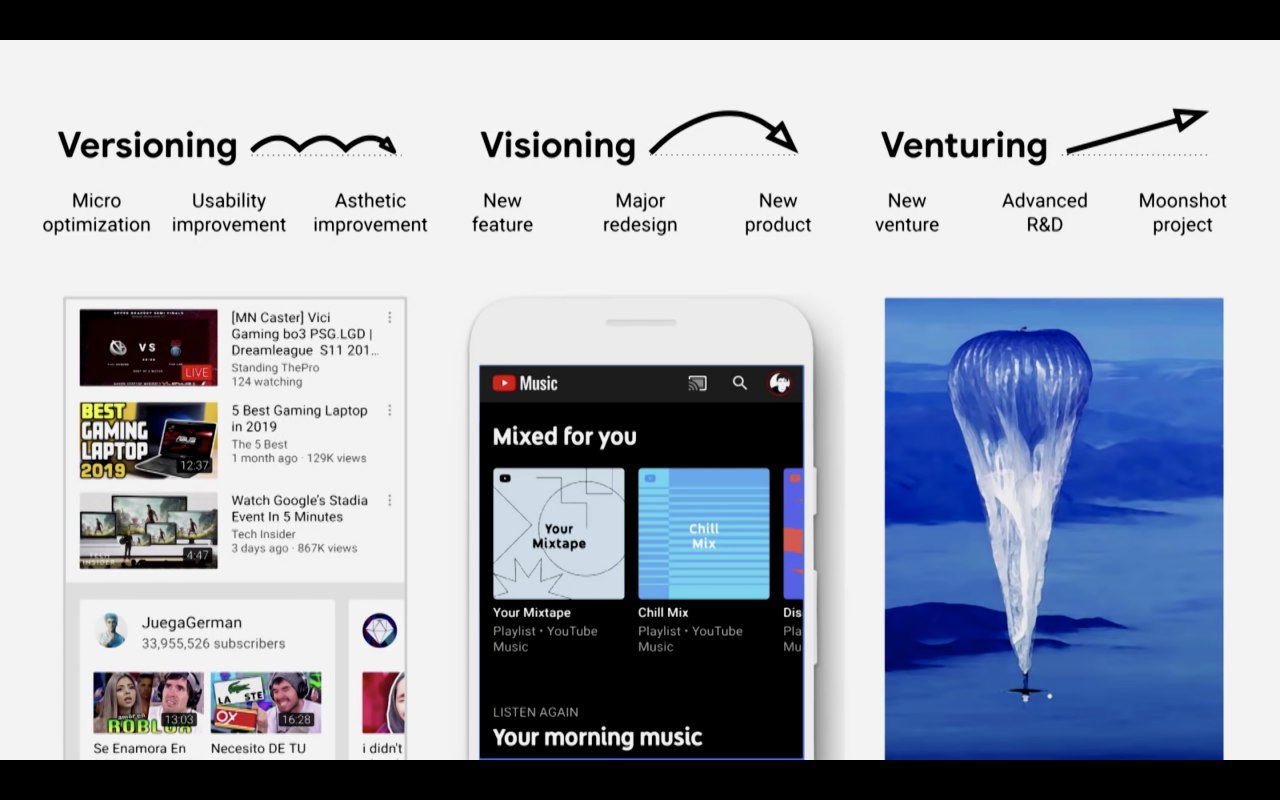
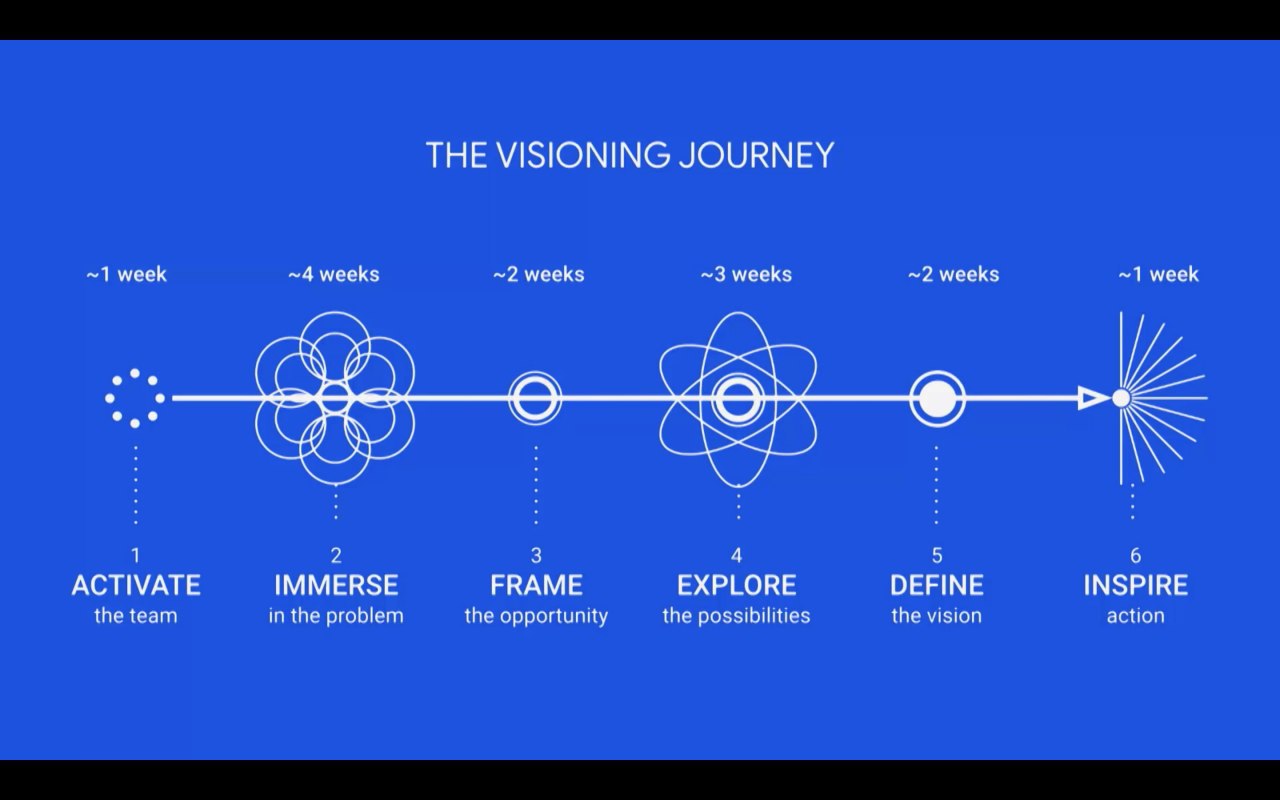
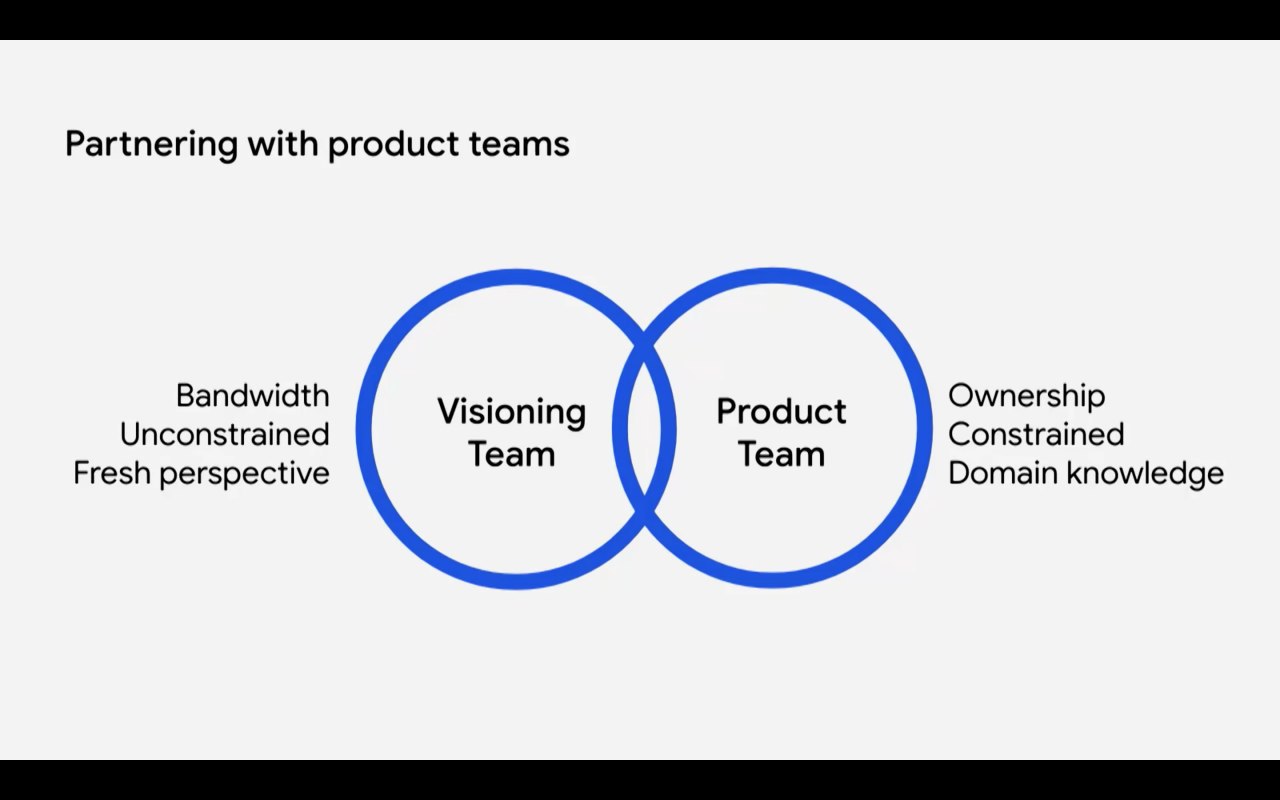
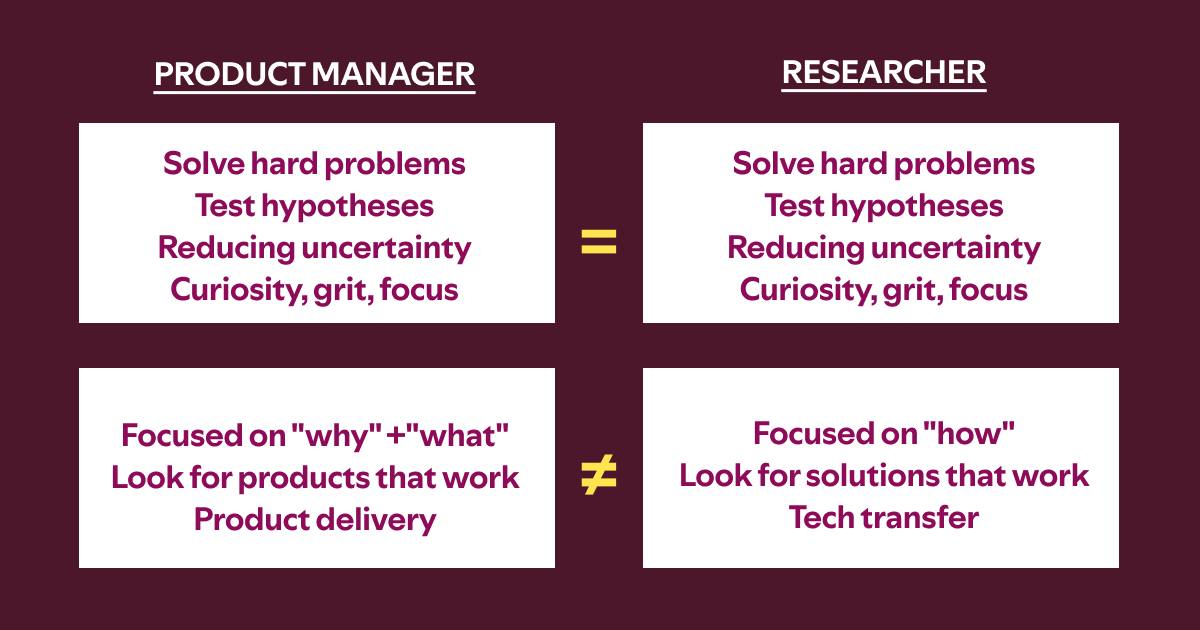
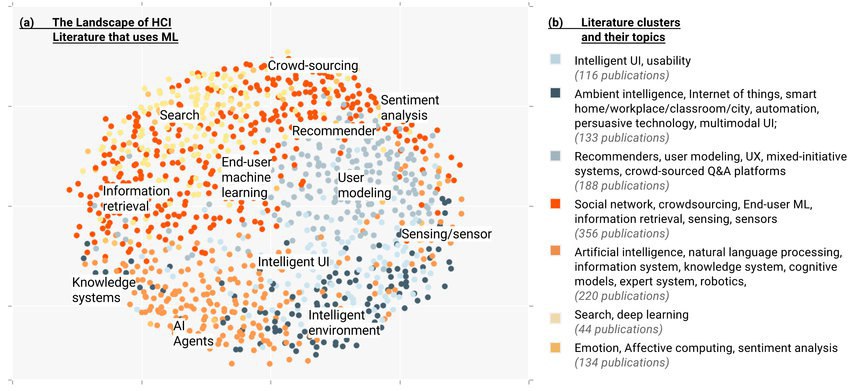
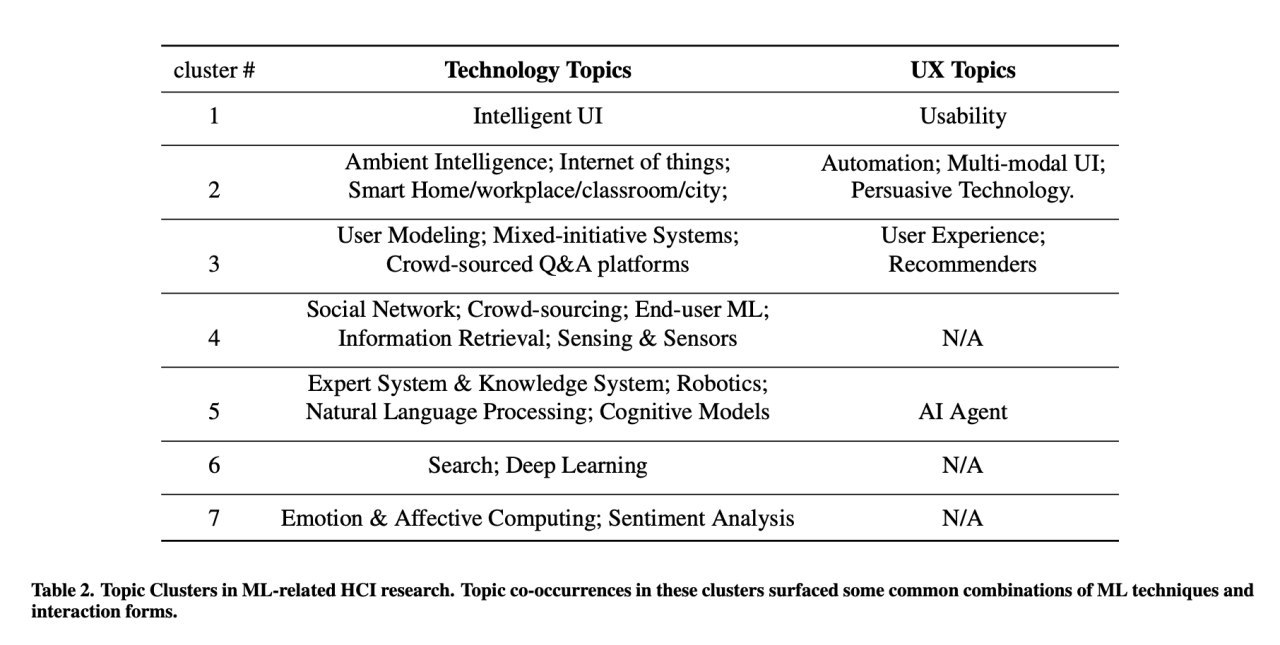
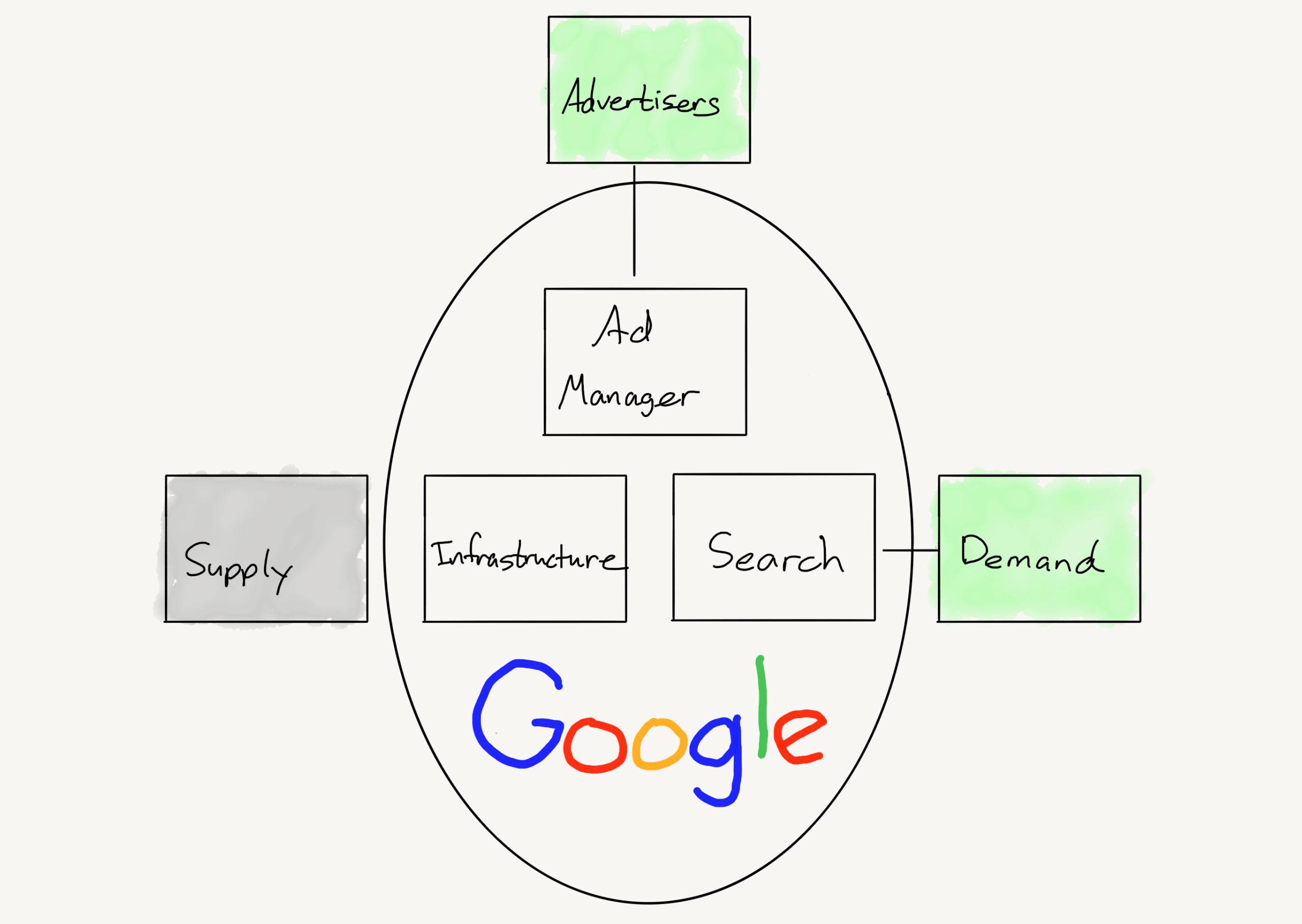
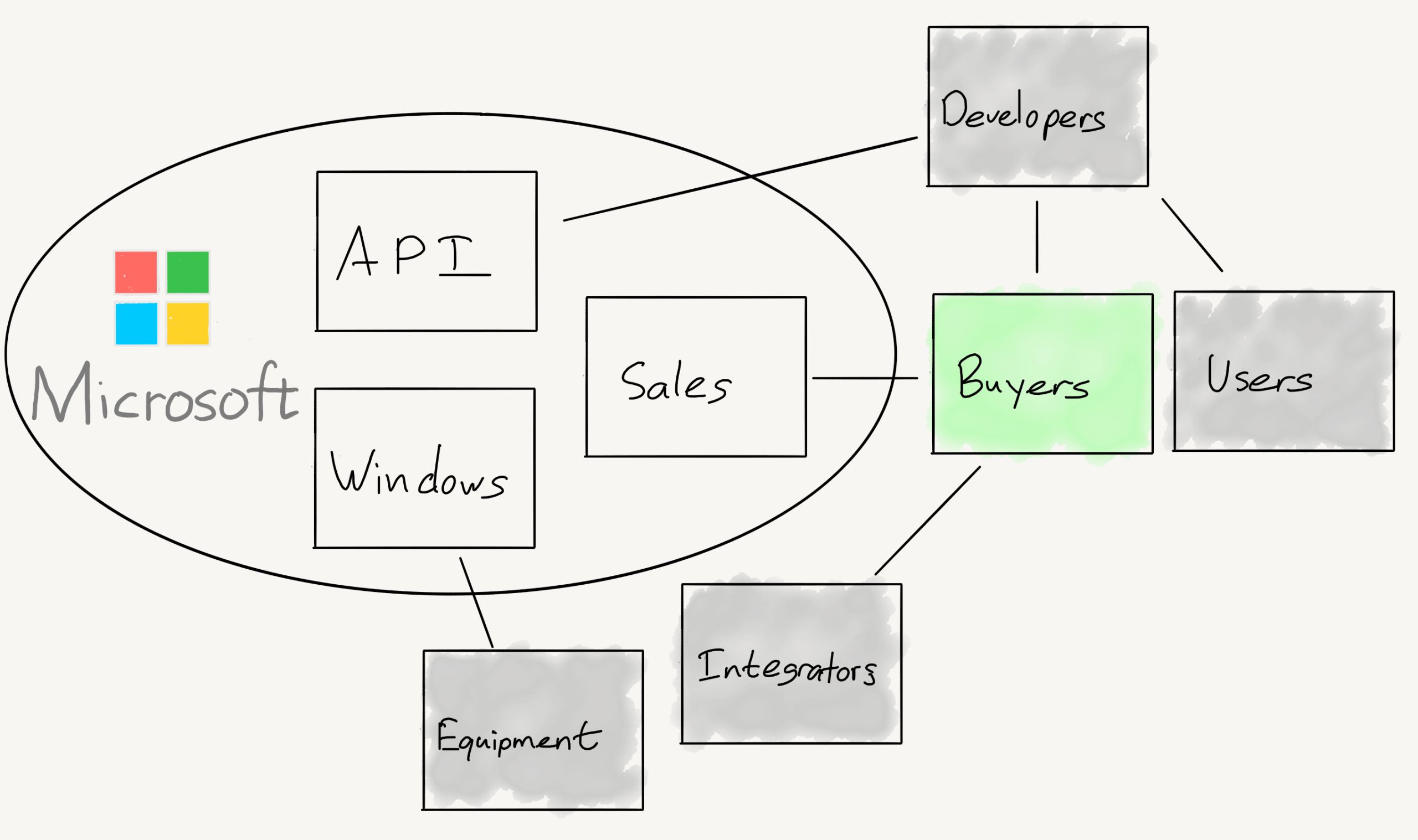
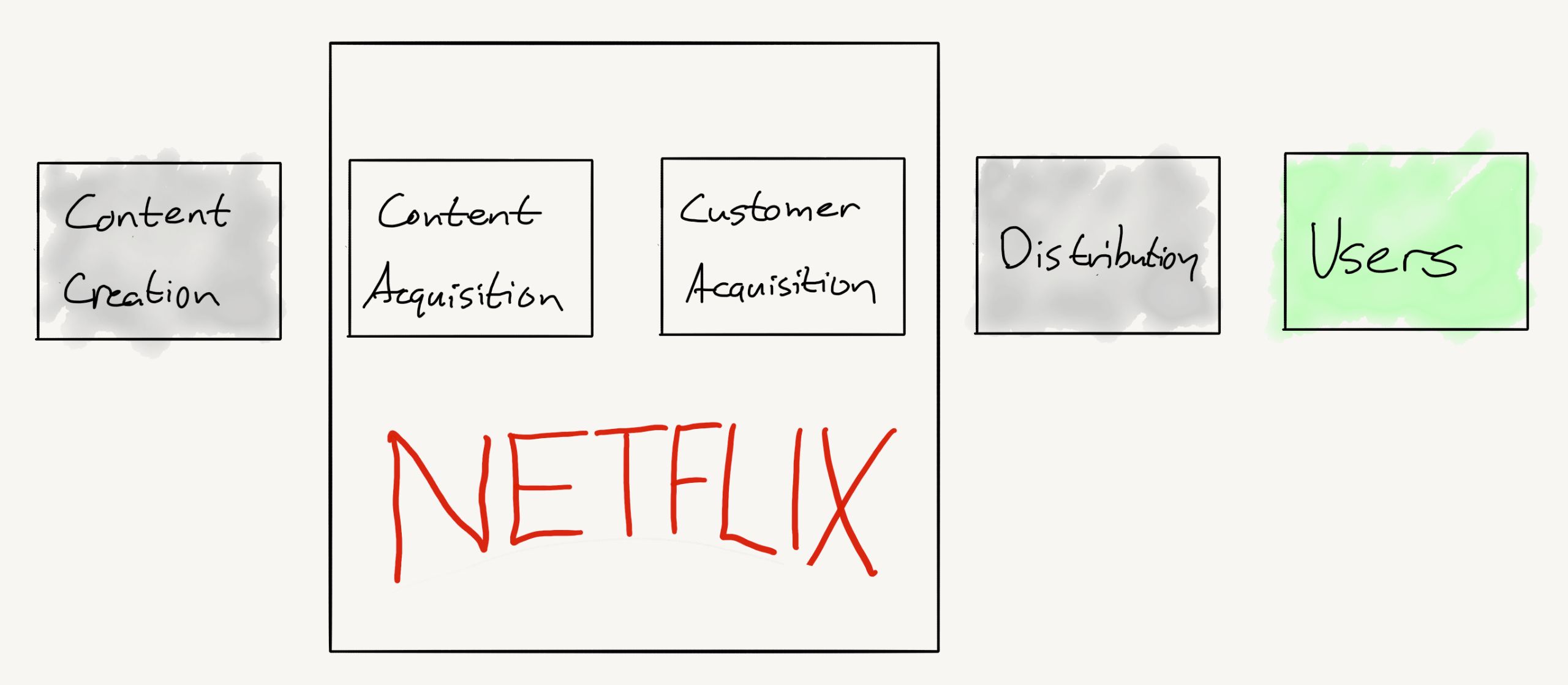
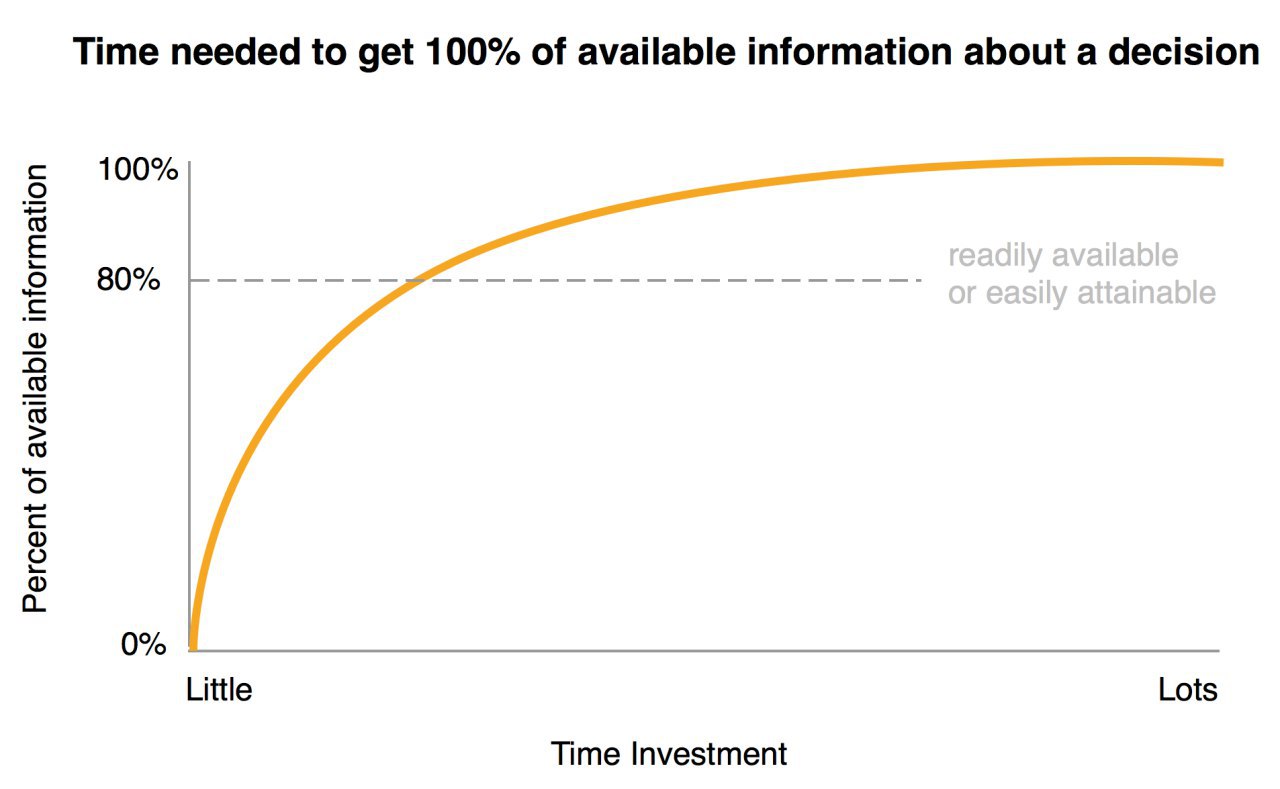
Что такое «метрика»?
Это число, которое характеризует какое-либо из свойств наблюдаемого процесса. Процессы в реальной жизни очень сложные и для глубокого понимания обычно используется набор метрик. Они смотрят на процесс с разных углов.
Метрики помогают собирать обратную связь с наблюдаемого явления. На основе обратной связи идет корректировка дальнейших действий. Термин «обратная связь» изначально появился в механике и инженерии. Постепенно он стал использоваться в менеджменте, клиентском сервисе и разработке продуктов.
Вот как описывают фидбек на «общем уровне»
Feedback is as a generic method of controlling a system by using past results to affect future performance. Approaches which keep a system operating within tight parameters, demonstrate negative feedback. That’s not pessimistic or bad feedback, but feedback that prompts the system to maintain control. Negative feedback is actually good feedback because it yields greater efficiency and performance. Positive feedback, by contrast, causes the system to keep going, unchecked. Like a thermostat that registers the room as too warm and cranks up the furnace, it’s generally meant to be avoided.
“Negative feedback is actually good feedback because it yields greater efficiency and performance.” — James Watt, Scottish inventor & mechanical engineer.
Число в вакууме не несет смысла. Для получения пользы от метрики мы должны сравнить ее с другим показателем. Примеры:
- сравнивая свои показатели со стандартами (бенчмарками) индустрии, можно понять наше положение на рынке.
- отслеживая показатели во времени, можно понять как развивается наша компания относительно «прошлой» себя.
Свойства хорошей метрики
- Консистентность (воспроизводимость) результатов (англ. reliability) — если повторить исследование/эксперимент, то мы получим те же числа.
- Валидность (англ. validity) — мы уверены, что метрика измеряет именно то, что мы хотим замерить.
- Чувствительность (англ. sensitivity) — метрика хорошо реагирует на изменения.
Если метрика не удовлетворяет этим критериям, то мы получаем неверную обратную связь на наши действия от окружающей среды.
Метрики в UX
Измерение в UX — это количественная оценка наблюдений и мнений пользователей. Они помогают снизить неопределённость относительно того, насколько удобно пользоваться продуктом на самом деле.
UX-метрики оценивают качество взаимодействия человека с интерфейсом при выполнении определенной задачи. Понятие «задачи» многогранно, обычно выделяют три уровня. Естественно, границы уровней размыты. Разберем на примере поискового продукта:
- Макро — найти нужную информацию в поисковике.
- Мезо — прочитать результаты выдачи, переформулировать вопрос.
- Микро — ввод запроса, построчное сканирование текста в ответе.
Альтернативная классификация:
- микро- и мезо-уровни еще иногда называют юзабилити-метриками.
- макро-уровень иногда называют Customer Experience (CX-метрики). Такие метрики можно использовать на уровне всего продукта или бизнеса.
User Experience vs. User Centric
Эти понятия легко спутать. UX-метрики это подмножество User Centric метрик. Но не все User Centric метрики являются UX.
Примеры User Centric показателей, которые не являются UX-метриками:
- User-Level LTV — показывает сколько мы заработаем с определенного пользователя безотносительно используемого продукта/услуги.
- Количество сессий на человека — показывает активность человека в продукте, но ничего не говорит про «качество» это взаимодействия.
- Средняя скорость загрузки страницы на человека — замеряет техническое свойство продукта, но не говорит о том, как пользователь это воспринимает.
- NPS — замеряет лояльность потребителей к бизнесу, но не говорит о качестве реализации конкретной задачи или сценария.
Эти метрики также отталкиваются от человека, но абстрагируются от интерфейса и/или задачи, а работают уровне продукта или бизнеса. Это не означает, что UX-специалисты не используют их в работе. Такие метрики являются хорошим мостиком между дизайном, продуктом и бизнесом.
Списки User Centric метрик
Популярные UX-метрики
В конце 80-х начался период компьютеризации бизнеса и многие компании хотели понять, стоит ли вообще в это вкладываться. Тогда и пошел «заказ» от корпораций в университеты и другие исследовательские организации на разработку методологий оценки эффекта он внедрения IT.
Ученые использовали имеющийся аппарат из психологии, социологии, эргономики, экономики и других наук, чтобы придумать индикаторы, которые удовлетворяют «свойствам хорошей метрики» (смотри начало статьи).
Вот что входит в «джентльменский набор»...
System Usability Scale (SUS)
Самый известный и, наверное, старый способ измерения удовлетворения от интерфейса — это опросник System Usability Scale (SUS).
После работы в системе, респондент проходит опрос из 10 вопросов. По определенной формуле считается показатель, который лежит в диапазоне от 1 до 100. Он характеризует сложность интерфейса:
- 1 — непонятно, от слова «совсем»
- 100 — «божественный» UX
Количество вопросов — это главная проблема, которая не позволяет собирать SUS с неподготовленной аудитории. Поэтому, в основном, его замеряют на юзабилити-тестированиях. На практике была доказана сила связи между SUS и индексом лояльности к компании.
Single Ease Question (SEQ)
После совершения целевого действия, пользователя можно спросить вот такой вопрос:
seq-high-res.jpg
Доказано, что более легкие задачи делаются быстрее и бОльшее количество человек их заканчивает, т. е. выше конверсия.
Концепция «простоты использования» используется во многих других метриках. Например, за метрикой Customer Effort Score стоит простая идея, что чем проще пользоваться продуктом или услугой тем более лояльными будут клиенты. Но мне удалось найти какие-либо подтверждения на этот счет (хотя мысль логичная).
Также, между одним вопросом про «простоту использования» с огромным SUS есть корреляция 90%. Это еще один «плюсик в карму» для этой метрики.
Достоинство этой метрики в том, что ее можно замерять online, т. к. конверсия в ответ будет высокой. Если в продукте есть четкая воронка, то можно собирать оценки в конце пути.
Usability Metric for User Experience (UMUX)
Эта метрика разработана в качестве альтернативы SUS. Акцент делается на измерении двух свойств продукта: функциональность и простота.
В UMUX четыре вопроса, а в усовершенствованной версии UMUX-Lite их два:
Доказано, что UMUX-Lite может заменять SUS и при этом не терять в точности оценки. Два вопроса проще «уместить» в интерфейс продукта и начать спрашивать online, чем пользуются продуктовые компании.
Пример из жизни: как исследуют пользователей, расставляют приоритеты и снимают метрики в Atlassian.
Customer Satisfaction Score (CSAT)
Удовлетворенность — еще одна концепция в мире User Experience. Это популярная метрика, которую обычно спрашивают после завершения какого-либо сценария. Самый популярный вариант — после обращения в техническую поддержку.
How would you rate your overall satisfaction with the [goods/service] you received?
Но есть примеры, когда CSAT измеряется уровне всего продукта или компании. American Customer Satisfaction Index уже больше 20 лет каждый год опрашивает сотни тысяч американцев на предмет удовлетворенностью продуктами или услугами компаний из разных сфер и индустрий.
Интересно, что между CSAT компании и ее финансовыми показателями имеется хорошая связь. Историю и бенчмарки можно найти на этом сайте.
Single Usability Metric (SUM)
Это 6 показателей, которые по хитрой формуле превращаются в число от 1 до 100. Эти показатели включают в себя:
- Метрики на основе поведения респондентов
- Справился ли респондент с задачей
- Фактически проведенное время над задачей
- Количество ошибок
- Субъективные метрики-опросы с 5-бальной шкалой для ответа:
- Воспринимаемое время над задачей
- Воспринимаемая сложность
- Удовлетворенность (тот же самый CSAT)
По задумке авторов, эта комбо-метрика предоставить более взвешенный взгляд на пользовательский опыт и упростить принятие решений. Многие агентства и компании ее используют, но открыто не делятся опытом.
К счастью, Microsoft поделилась своим 2.5-летним опытом ее использования. Инсайты:
Шкала от 1 до 100 непонятна стейкхолдерам. Где отсечка, после которой «все хорошо?»
Фактическое и воспринимаемое время над задачей не всегда коррелируют. Люди иногда отвлекаются или просто «тупят», но при этом считают, что с задачей справляются быстро. Время — это шумная метрика.
Количество ошибок на практике заранее неизвестно наперед. Поэтому с точки зрения метрики это просто шум.
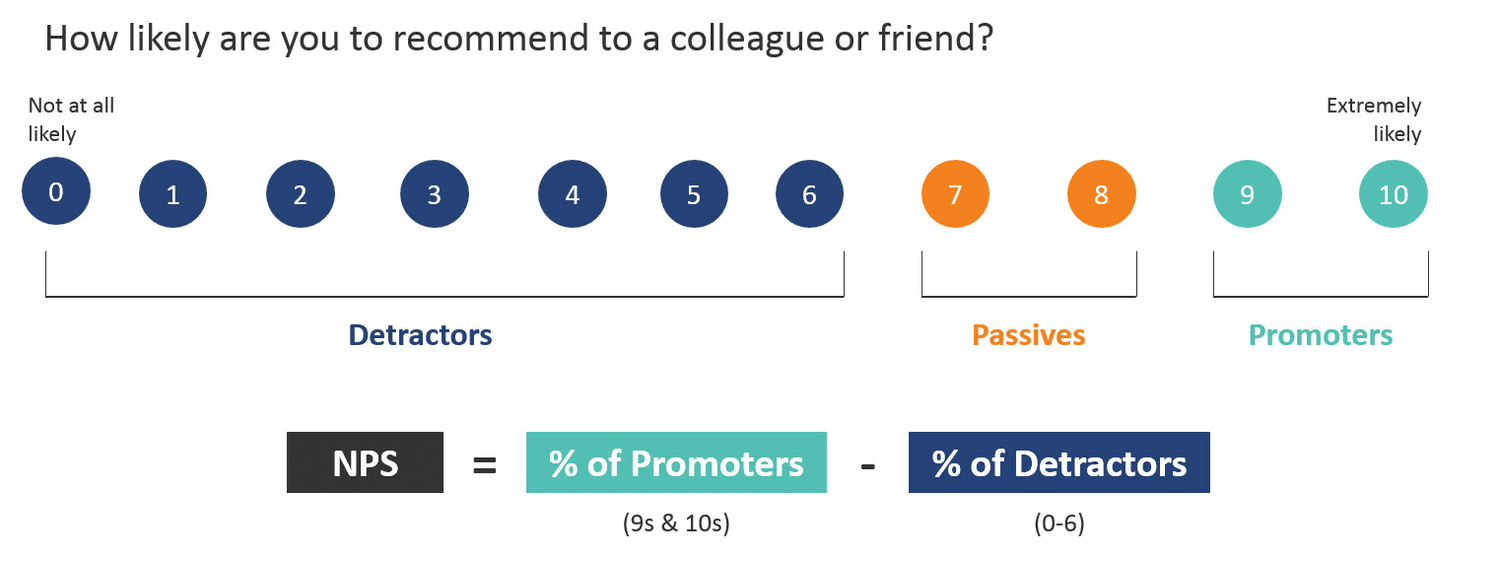
Net Promoter Score (NPS)
Очень популярная метрика лояльности потребителя к бренду или услуге. Поэтому остановимся на ней подробнее.
У этой метрики есть «набирающий популярность брат» Actual NPS (aNPS), который пытается устранить одну из ошибок NPS — спрашивать про мнение и будущее.
Но это не самая главная беда этой метрики в контексте измерения UX. Бренд «собирает» под собой не только продукт с его дизайном, но и работу поддержки/отдела продаж и новости о бренде.
Слишком много факторов влияет на NPS.
На практике мы получаем слабую чувствительность к UX-изменениям. Сторонними исследователя установлено, что «вклад» UX в NPS составляет не более 66%.
Но есть ситуации, когда NPS можно использовать как UX-метрику:
- Если респондент не знает, продукт какого бренда он тестирует / использует.
- Если весь продукт держится только на одной макро-задаче и можно пренебречь влиянием других факторов
Примеры, когда NPS подходит и не подходит как UX-метрика.
- Порекомендуете ли вы AdBlock друзьям или коллегам?
- ОК, т. к. основной сценарий в AdBlock — это блокировка рекламы на сайтах. Однозначная ассоциация.
- Порекомендуете ли вы Wrike друзьям или коллегам?
- НеОК
- Wrike это продукт с множеством макро-задач внутри: планирование проектов, управление ресурсами, хранилище документации. Как понять, UX какого сценария дает больший вклад?
- Wrike используется для управления проектами и людьми. Есть люди, которые просто не любят работать, поэтому будут ставить плохие оценки в NPS даже если продукт будет идеален.
- Wrike это b2b-компания, в которой «продуктом» является не только сайт, но и поддержка, обучающие материалы и размер скидки, который может дать отдел продаж.
- Основные покупатели Wrike — топ-менеджеры. Рядовые сотрудники могут просто не иметь знакомых топ-менеджеров, которые ищут систему управления проектами. Некому рекомендовать.
- Некоторые люди «оставляют работу на работе» и не рекомендуют друзьям рабочие инструменты. А все коллеги и так уже пользуются этой системой.
Некоторые компании пытаются «уточнять» NPS и спрашивать про конкретный опыт в продукте. Но это тогда уже не NPS, а что-то другое. Примеры:
- С какой вероятностью вы порекомендуете продавать товары на Авито друзьям или коллегам?
- Порекомендуете ли вы слушать музыку в Spotify друзьям или коллегам?
Другие метрики
Существует еще большое количество UX-метрик. Какие-то требуют покупки лицензий, а какие-то используются в узкоспециализированных областях:
- Language Quality Survey (LQS) — метрика качества локализации
- Lostness — метрика качества навигации в продукте
- SUPR-Q, qxScore, User Experience Questionnaire (UEQ) и AttrakDiff — опроссники, которые продвигают идею единого числа в UX для всего и вся.
- И еще сотни других метрик...
Фреймворки и подходы
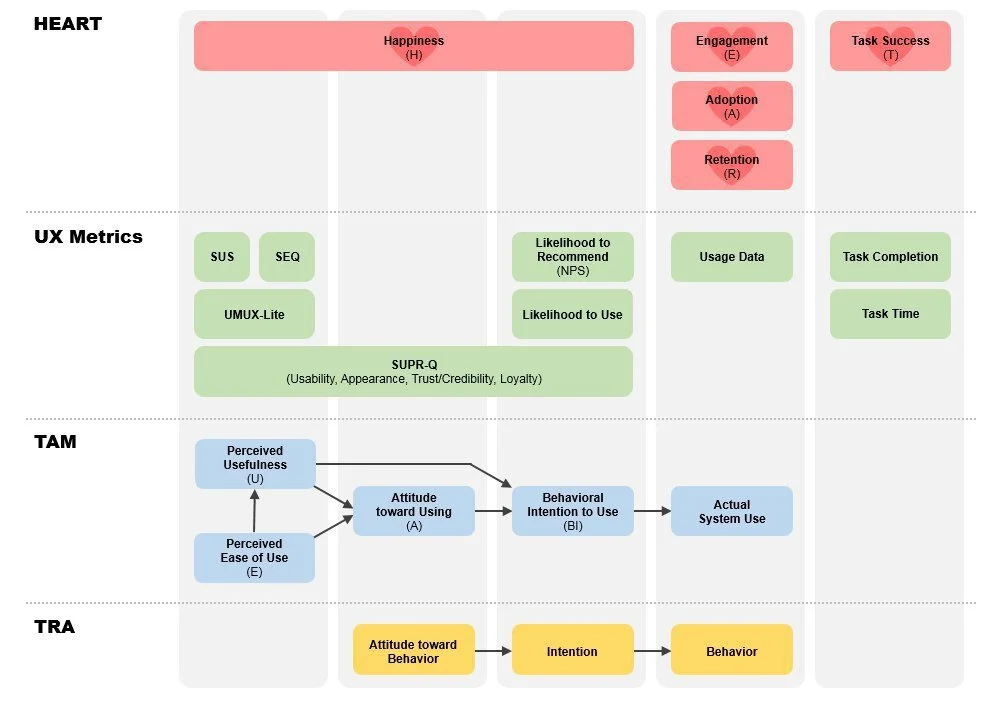
Метрик много, но не всегда понятно какую использовать под вашу задачу. Google в 2010 году опубликовала научную работу по HEART — подход, который помогает выбрать метрику для измерения пользовательского опыта под разными углами. Фреймворк был опробован на 20 проектах внутри Google, а затем пошел “во вне” компании.
HEART комбинирует мнения пользователей через опросы и поведенческие продуктовые метрики
Tomer Sharon, бывший UX Researcher в Google и WeWork и нынешний глава по ресерчу в Goldman Sachs, расписал подробно про каждый “срез” сквозь призму своего опыта и дает примеры метрик:
Как и многое из Google, этот подход стал набирать популярность. Но это не единственное, что придумало человечество.
Главные Концепции
Как можно было заметить, UX-метрики работают с разными абстракциями:
Есть две модели, которые пытаются расположить их в иерархию и понять влияние друг на друга:
- American Customer Satisfaction Index (ACSI)
- Technology Acceptance Model (TAM)
Вот неполная схема взаимосвязи метрик
Запомнить
- Метрика нужна, чтобы собирать обратную связь из внешнего мира и корректировать свои планы. Числа без привязки к контексту никому не интересны.
- User Experience — это очень широкая область, поэтому и метрики в нем совершенно разные. Они могут фокусироваться на удобстве микро-взаимодействий пользователя с системой и на долгосрочных целях человека в продукте. Единого термометра не изобрели (хотя многие пытаются). Главное — UX-метрики замеряют восприятие человека.
- Сделать достоверную метрику очень сложно. Изучите стандартные способы измерения пользовательского опыта, которые используется повсеместно. Не придумывайте велосипед.
- Для систематизации работы используйте HEART-фреймворк от Google. Освоив этот инструмент, пробуйте новый или придумайте свой подход.
- Все измерения в UX крутятся вокруг ограниченного набора концепций. Будут придуманы новые метрики, а концепции будут неизменны.
Статья впервые была опубликована в старом блоге по ссылке https://www.martsen.me/blog/quantifying-the-user-experience