Ключевые идеи из статьи Using Friction As A Feature In Machine Learning Algorithms, дополненные небольшими фатками автора из личного опыта.
NB! Слово «friction» в переводе с английского означает «трение» или «разногласие», что не совсем подходит в контексте пользовательского опыта. Поэтому далее по тексту я буду переводить «friction» как «помеху», т. к. счел это более подходящим вариантом. Теперь про идеи из статьи...
1. Иногда нужно локально усложнять пользовательский опыт, чтобы упростить его в целом
Популярные цифровые продукты оттачивают ключевые сценарии до состояния «действий в один клик (или вообще без него)». Есть даже известная в дизайн-сообществе книга на тему. Но как и любая механика бездумно доведенная до крайности, она может привести к нежеланным для бизнеса и/или пользователя последствиям.
Поэтому иногда проектироващики осознанно вставляют юзерам палки в колеса:
- Заставлять настраивать и/или собирать доп.инфу перед начало использования приложения (ох уж эти любимые N экранов в первой сессии, которые большинство людей пролистывают не глядя...)
- Подталкивать к определенным действиям при помощи механик из поведенческой экономики (интересующиеся могут поискать Nudge Theory)
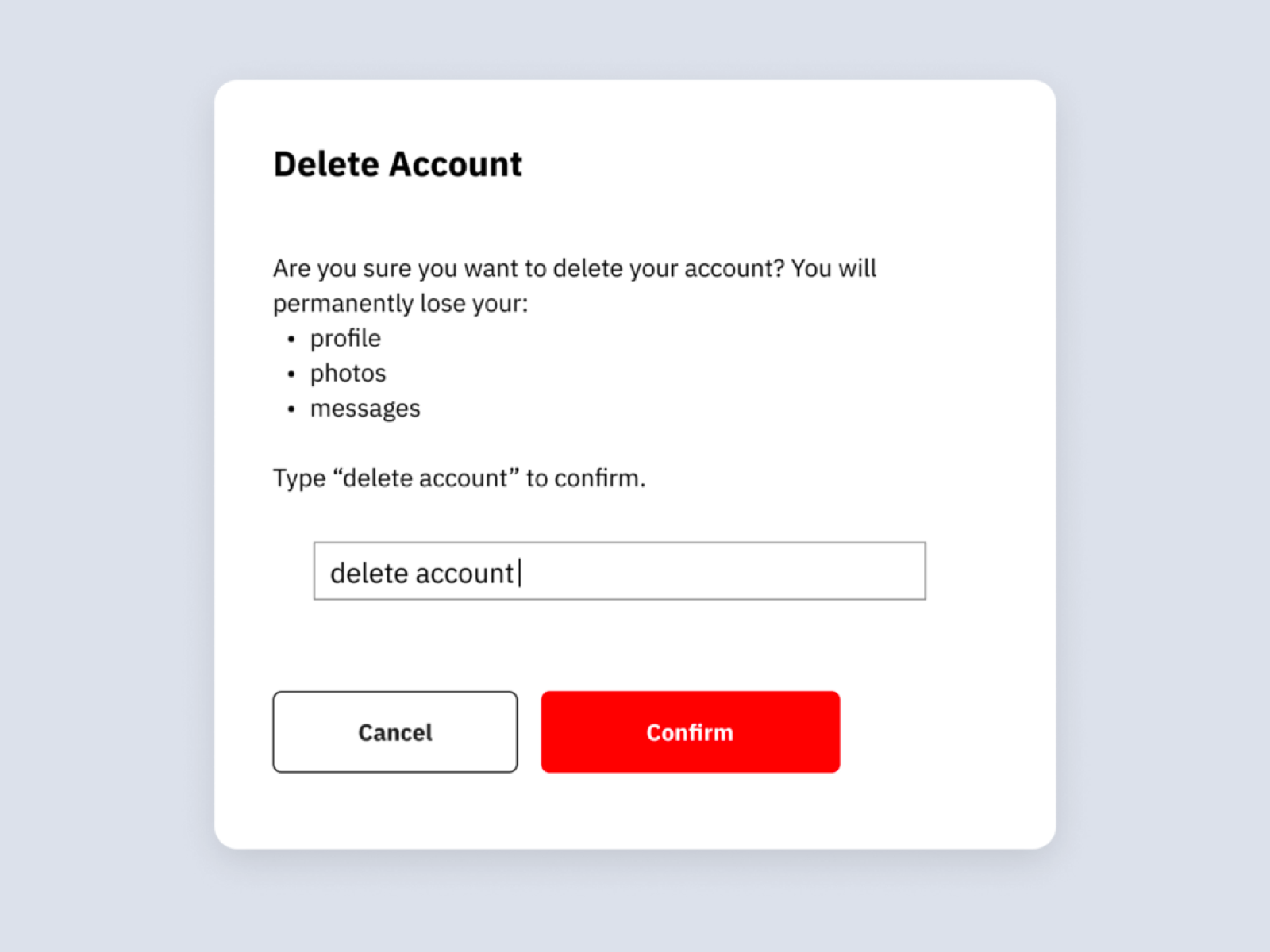
- «Защита от дурака» при критический действиях (напр., удаление данных)
Модальное окно, которое заставляет задуматься и напрячься, чтобы реально удалить учетную запись
2. UX-помехи позволяют отделять «сигнал» от «шума» и повышать качество рекомендаций
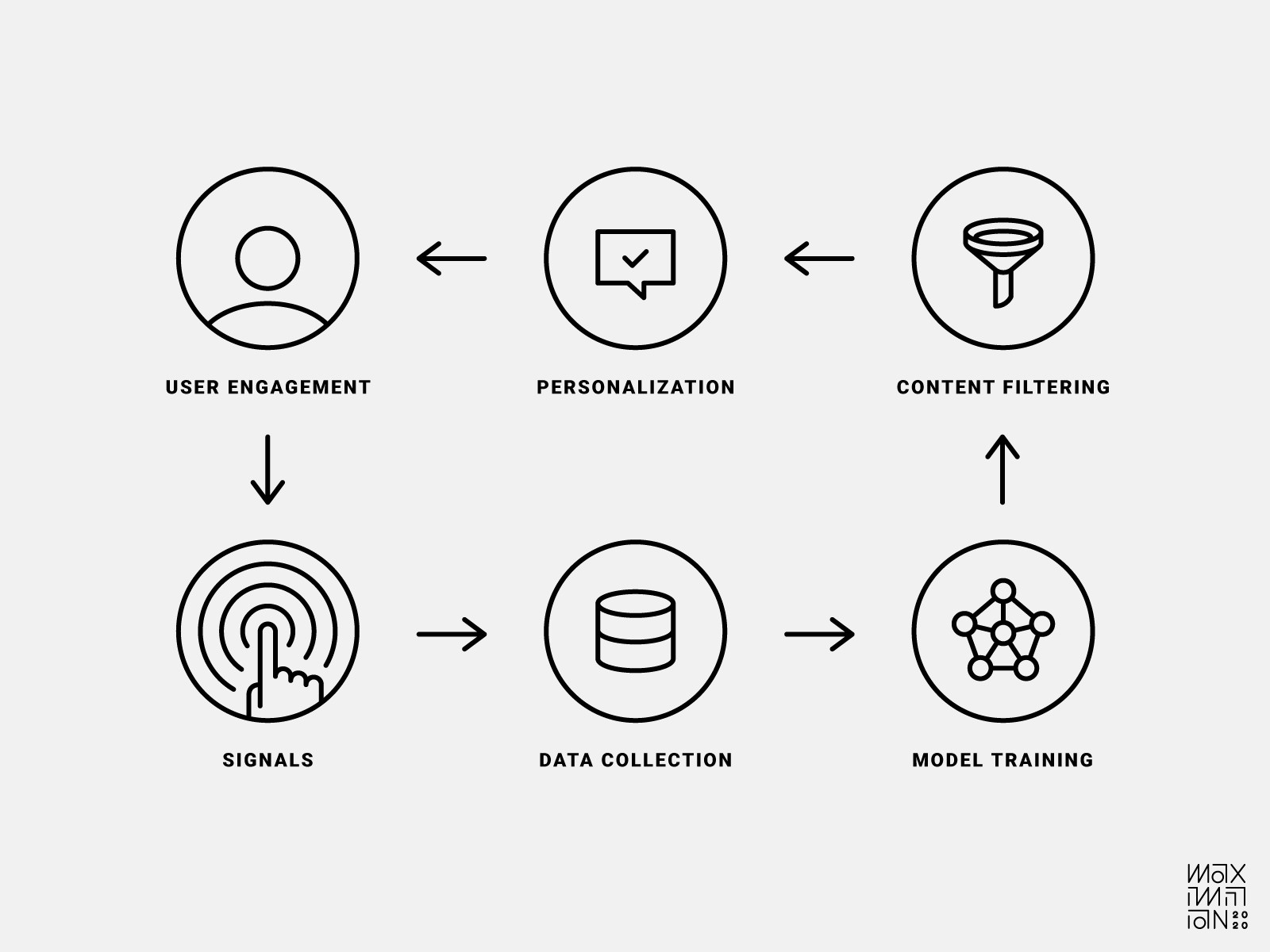
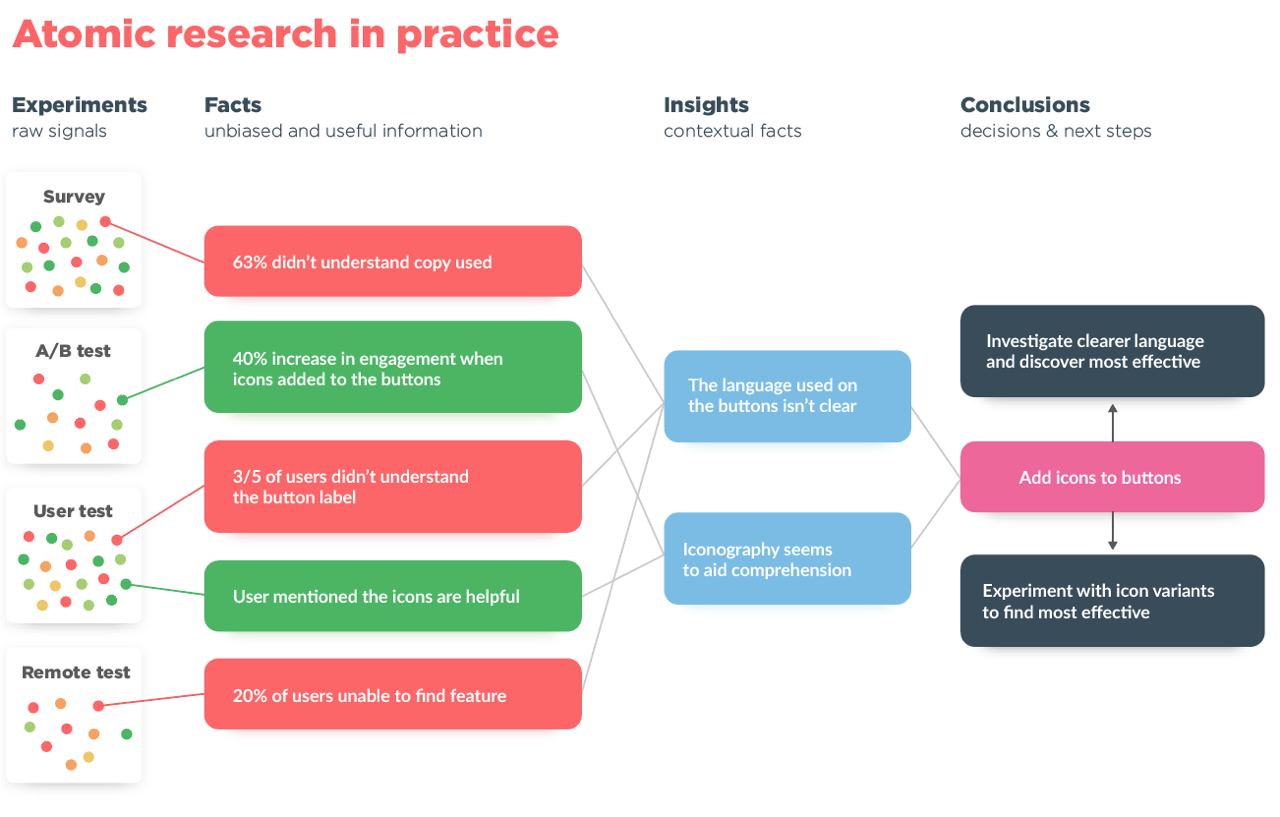
Для работы рекомендательных алгоритмов, продукт должен собирать сигналы от пользователя, обрабатывать их, а результат обратно отображать у пользователя. Думаю, если вы пришли в этот блог, то знаете это и без меня. Но на всякий случай прикладываю схему, которую сделал автор оригинального поста:
Цикл обратной связи типичного сервиса с движком рекомендаций
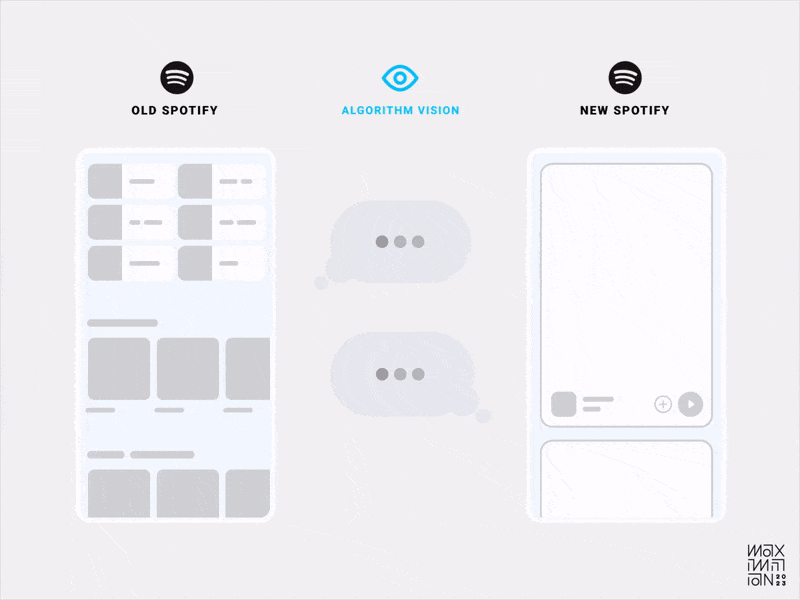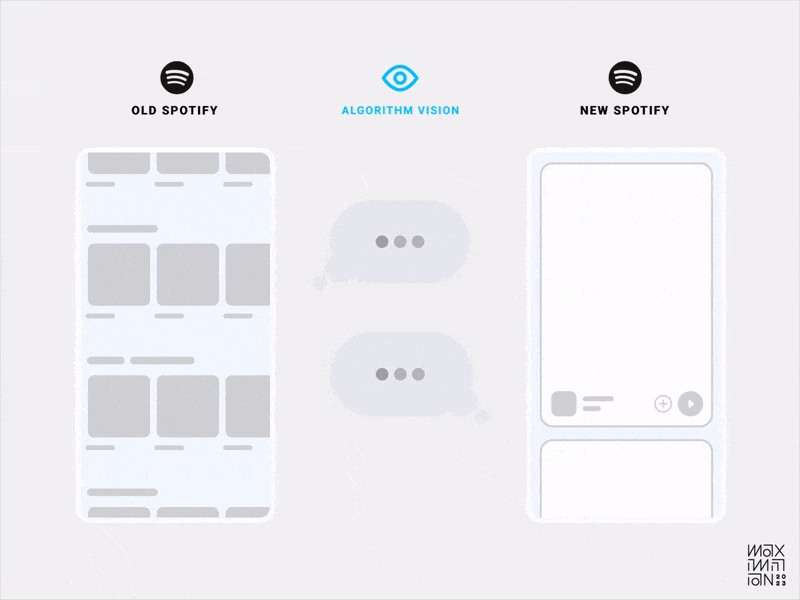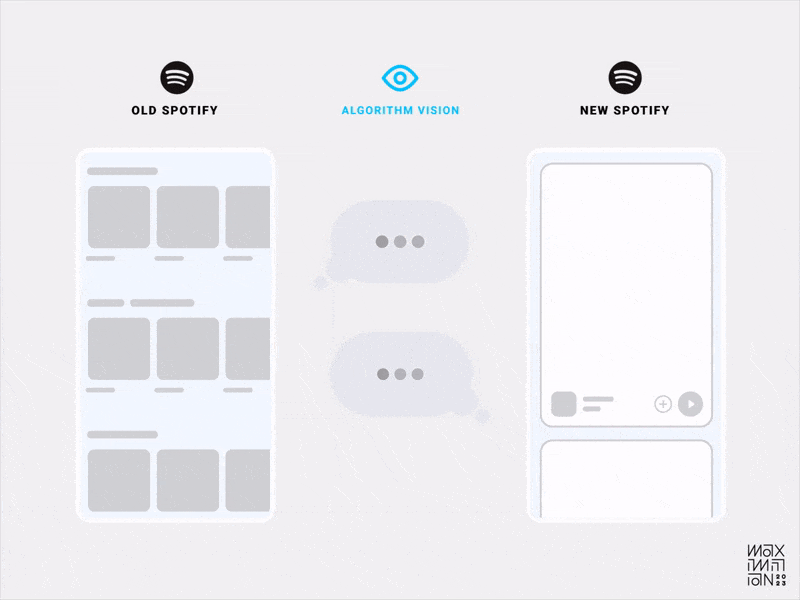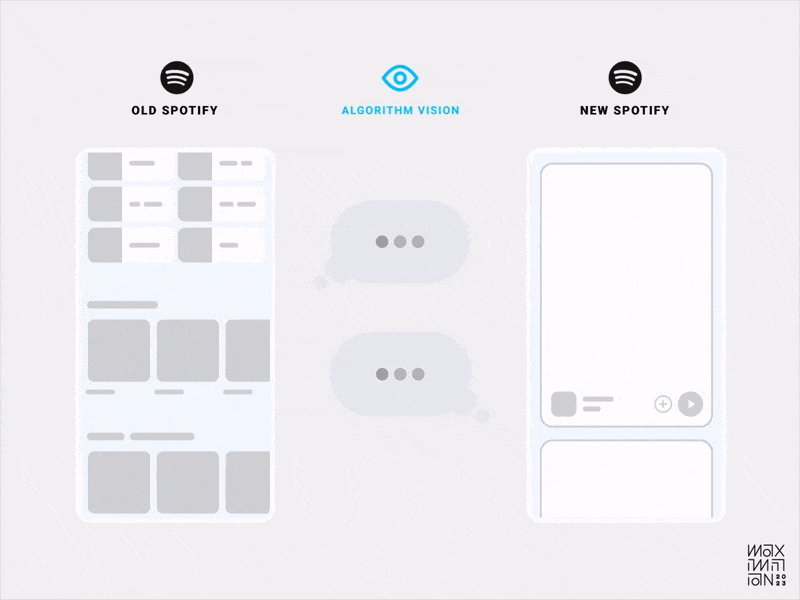
В свое время Tinder ввел дизайн карточек, который фокусирует человека на одном профиле за раз и механику свайпов, которая явным образом собирала оценку от пользователя.
TikTok взял эту механику на вооружение и довел до совершенства для своих целей — быстрее подстроиться под вкусы пользователя и затянуть в продукт. Но как это сработало?
TikTok не стал использовать «традиционный» дизайн в виде витрины контента, который:
- позволяет широким взглядом охватить имеющийся каталог, но...
- мешает алгоритму недвусмысленно понимать что захватывает внимание пользователя, а что нет
Получается, что эта механика ухудшила один аспект опыта (человек видит меньше контента за раз), но позволила быстрее подстраивать ленту и улучшить опыт взаимодействия с сервисом в целом.
А еще, у TikTok в первой сессии нет привычного онбординга из нескольких экранов, где можно настроить приложение. Настройка происходит по мере скролла ленты, что сокращает время до получения ценности от продукта.
В марте 2023 музыкальный сервис Spotify выкатил редизайн своего продукта, в котором показал ленту а-ля TikTok. Верховный продуктолог и по совместительству глав.инженер сервиса, обстоятельно объяснил в интервью почему они радикально меняют интерфейс.
“Секрет того, почему некоторые из продуктов так хороши в рекомендациях, на самом деле заключается не в том, что у них лучшие алгоритмы. Это те же самые алгоритмы с более эффективным пользовательским интерфейсом”.
— Густав Седерстрем в статье The Verge “Почему Spotify хочет выглядеть как TikTok”
Интересно, что их редизайн собирает хейт по интернету. Например, Mashable назвал новый интерфейс Spotify одним из худших обновлений 2023 года. Но руководство музыкального сервиса готово мириться с критикой, т. к. в долгосроке верит в правильность своего решения.
So What?
В статье есть еще несколько рассуждений про потенциальное использование этой механики в будущем и в других ML-продуктах. Не обошлось и без упоминания модных нынче языковых моделей. И есть несколько советов как искать «полезные помехи», но они как-будто слишком абстрактные.
В целом, метериал годный и содержит ряд полезных релевантных ссылок. Не зря потратил 15 минут на чтение. Можно ссылаться на него при рабочей необходимости.